Motivation
With the approaching exascale era, HPC architectures undergo radical changes. The increase in compute cores per processor/node and the rise of exascale hardware require “MPI+X” programming approaches. Fault-tolerant approaches need to account for hard- and software failures at exascale. Optimal exploitation of respective supercomputers becomes more and more important, due to the high energy consumption of these huge systems. These and many other issues pose challenges for the programmers and the users of respective soft- and hardware. In particular, the usual tuning approach
- Choose an optimal algorithm; go to 2
- Optimize at node-level; investigate performance and pot. revise 1,2; go to 3
- Optimize at distributed memory level; investigate performance and pot. revise 1,2,3; go to 4
- Optimal software solution found
becomes very complex.
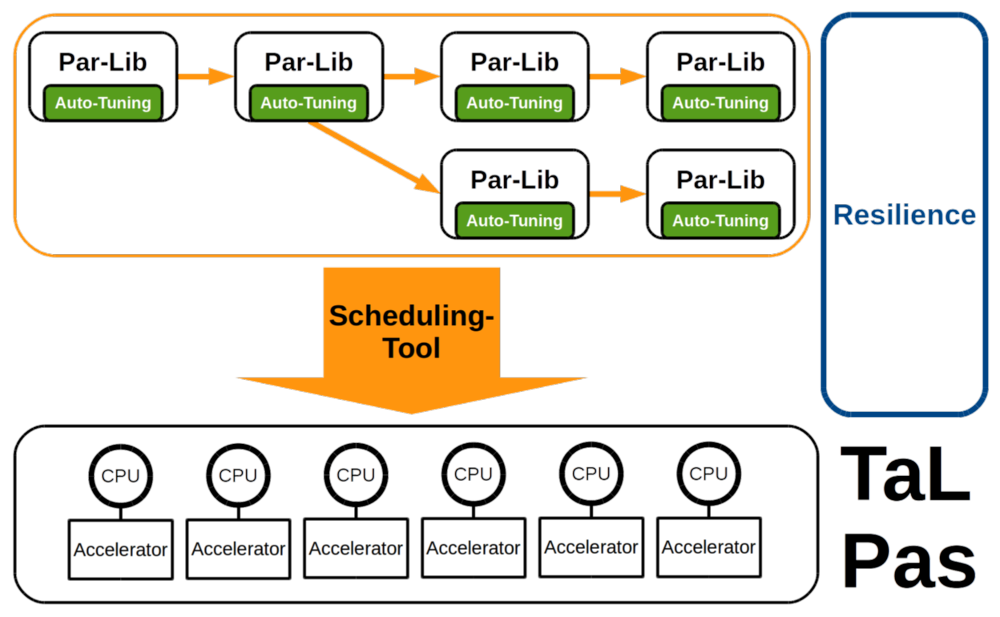
In this regard, the project TaLPas: Task-basierte Lastverteilung und Auto-Tuning in der Partikelsimulation targets an auto-tuning and task-based approach to high-performance particle simulations. Particle simulations are used in a wide range of problem settings such as molecular dynamics, fluid dynamics, or astrophysics.
Objectives
The main goal of TaLPas is to provide a solution to fast and robust simulation of many, potentially dependent particle systems in a distributed environment.
This is required in many applications, including, but not limited to,
- sampling in molecular dynamics: so-called “rare events”, e.g. droplet formation, require a multitude of molecular dynamics simulations to investigate the actual conditions of phase transition,
- uncertainty quantification: various simulations are performed using different parametrisations to investigate the sensitivity of the parameters on the actual solution,
- parameter identification: given, e.g., a set of experimental data and a molecular model, an optimal set of model parameters needs to be found to fit the model to the experiment.
For this purpose, TaLPas targets
- the development of innovative auto-tuning based particle simulation software in form of an open-source library to leverage optimal node-level performance. This will guarantee an optimal time-to-solution for small- to mid-sized particle simulations,
- the development of a scalable task scheduler to yield an optimal distribution of potentially dependent simulation tasks on available HPC compute resources,
- the combination of both auto-tuning based particle simulation and scalable task scheduler, augmented by an approach to resilience. This will guarantee robust, that is fault-tolerant, sampling evaluations on peta- and future exascale platforms.
VISUS Subproject
The VISUS subproject is tasked to examine approaches related to the resilience problem. One possible way of implementing resilience is checkpointing. However, with the sheer size of the data produced a commonly used 'dump time step to disk' approach is not feasible. To support the checkpointing effort, we are developing a new file format, which supports very generic and heterogeneous systems.
This new file format, and its accompanying API, has several objectives:
- Integrate effortlessly with the simulation software. The API should be lightweight and easy to use.
- It should minimally impact the simulation applications processes. Optimally, the API only uses idling processes, and exploits any hardware extension tailored to Input/Output tasks.
- The data produced by the simulation is preprocessed. To minimize storage space, as well as enable fast post-processing by e.g. a visualization, the data is reduced in-situ, i.e. on the compute nodes of simulation which generates them.
A second task of the subproject is providing an analysis of the data generated by the project's solvers. For this, custom-tailored analysis applications are developed. The currently implemented analysis deals with the examination of ensembles, as it is for example needed for the Parameter Identification task of the project.