Motivation
Mit dem Anbruch der Exascale Ära haben HPC Architekturen einen radikalen Wandel vollzogen. Die steigende Anzahl der Rechenkerne pro Prozessor und der Anstieg von Hardware, die auf Exascale ausgelegt sind, benötigt "MPI+X" Softwarelösungen. Auch fehlertolerante Ansätze müssen das Versagen von Hard- und Software auf Exascale-Skalen berücksichtigen. Optimale Ausnutzung diverser Supercomputerarchitekturen wird zunehmend wichtiger, insbesondere durch den hohen Energieverbrauch dieser großen Systeme. Diese und andere Probleme stellen neue Herausforderungen für Programmierer und Nutzer.
Insbesondere versagt die herkömmliche Herangehensweise bei komplexen Systemen:
- Wähle einen optimalen Algorithmus
- Optimiere auf Knotenebene
- Optimiere auf verteilter Ebene
- Optimale Lösung
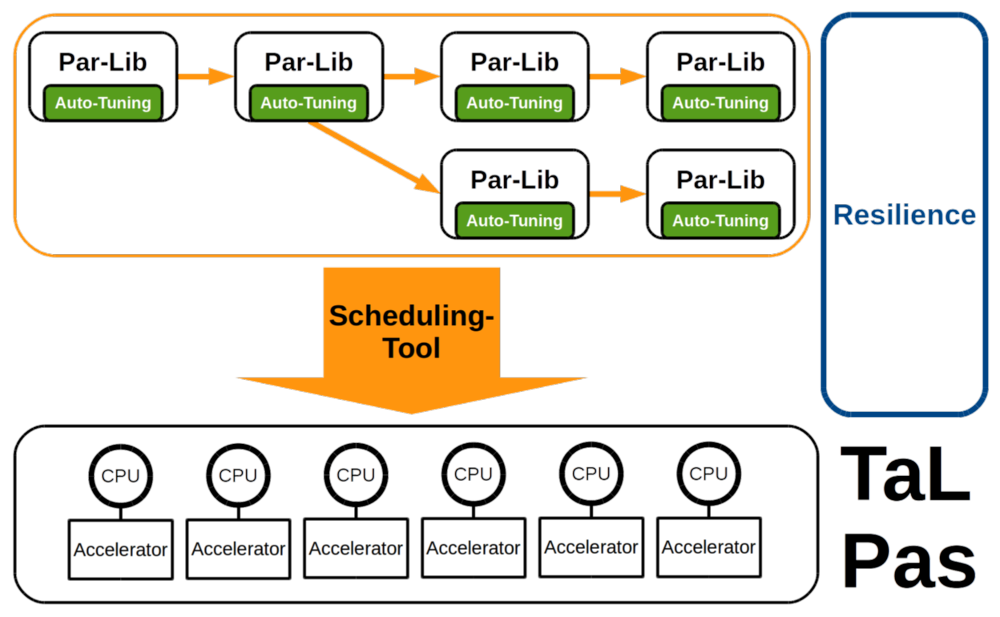
In dieser Hinsicht zielt das Projekt TaLPas: Task-basierte Lastverteilung und Auto-Tuning in der Partikelsimulation auf einen auto-tuning und task-basierten Ansatz für hochperformante Partikelsimulationen ab. Partikelsimulationen werden für diverse Bereiche der Forschung benötigt, wie zum Beispiel im Bereich der Molekulardynamik, Fluiddynamik oder Astrophysik.
Ziele und Aufgaben
Das Hauptziel von TaLPas ist, für mehrere, potentiell zusammenhängende Partikelsysteme, eine effiziente und robuste Lösung in verteilten System zu finden.
Dies wird von vielen Anwendung gebraucht, unter anderem für:
- Die Suche nach so genannten "rare events" in Molekulardynamik-Simulationen. z.B. benötigt das Finden von Tröpfchenausbildung eine Untersuchung vieler Simulationen mit variierenden Phasenübergangsbedingungen.
- Bewertung von Unsicherheitsfaktoren. Viele Simulationen werden verwendet um die Simulation auf die Empfindlichkeit bezüglich Parameteränderungen zu untersuchen.
- Parameteridentifizierung. Mit einem gegebenen Satz von experimentell erhobenen Daten und einem molekularen Modell, wird versucht geeignete Parameter des Modells zu bestimmen, so dass das Modell die Messwerte möglichst genau reproduziert.
Zu diesem Zweck zielt TaLPas ab auf folgende Ziele:
- Die Entwicklung einer innovativen, auto-tuning basierten Partikelsimulations-Software in Form einer open-source Bibliothek die optimale Leistung auf Knotenebene liefert. Dies kann eine optimal 'time-to-solution' für kleine bis mittlere Partikelanzahlen liefern.
- Die Entwicklung eines skalierbaren 'task scheduler', der die optimale Verteilung potentiell abhängiger Aufgaben auf verfügbaren Ressourcen eines Hochleistungsrechners verteilt.
- Die Kombination der optimierten Partikelsimulation und des skalierbaren 'task scheduler', mit zusätzlich verbessertem Ansatz für Stabilität. Dies wird robuste, fehler-tolerante Testevaluationen auf Peta -und in Zukunft auch Exascale Plattformen ermöglichen.
VISUS Unterprojekt
Die Aufgabe des VISUS ist die Untersuchung des Stabilitätsansatzes. Eine Möglichkeit diese umzusetzen ist das sogennante Checkpointing. Allerdings ist der herkömmliche Ansatz, bei dem einfach die Daten and ein angeschlossenes Speichersystem abgelegt werden, mit den nun riesigen anfallenden Datenmengen nicht mehr machbar. Um den Stabilitätsansatz zu verbessern, entwickeln wir ein neues Datenformat, das generische und heterogene System unterstützt.
Dieses neue Datenformat, und die begleitende API, hat folgende Ziele:
- Einfache Integration in bestehendes Software. Die API sollte einfach zu verstehen und einzusetzen sein.
- Minimal Einwirkung auf den laufenden Simulationsprozess. Optimalerweise nutzt die API nur unbenutzte Ressourcen und verwendet dabei existierende dedizierte Input/Output Technologien.
- Vorbereiten der Daten. Um den benötigten Festplattenspeichen zu minimieren, als auch das schnelle Verarbeiten, z.B. durch ein Visualisierungssystem zu ermöglichen, werden die Daten in in-situ reduziert, dass heißt direkt auf dem Knoten der die Daten erstellt.
Eine zweite Aufgabe des Unterprojekt ist eine Analyse der im Projekt anfallenden Daten. In diesem Rahmen werden unter anderem neue maßgeschneiderte Analysetechniken erstellt. Die aktuell entwickelte Analyse befasst sich mit dem Untersuchen von Ensembles, wie sie zum Beispiel für die Parameteridentifizierung benötigt wird.